


Come apprendiamo la capacità di ragionare sulle questioni morali? Come si sviluppa il nostro giudizio morale? Le macrocategorie all’interno delle quali si possono suddividere le risposte alla domanda sull’origine del giudizio morale sono principalmente due.
Da una parte, vi è la visione empirista, secondo la quale i meccanismi responsabili dell’apprendimento di un tratto psicologico o di una certa capacità sono generali per dominio. Con ‘generale per dominio’ si intende che i meccanismi attraverso i quali apprendiamo sono alla base dell’acquisizione di abilità, tratti o concetti molto diversi tra loro. Ad esempio, secondo una certa concezione dell’apprendimento, sarebbe sufficiente una storia di rinforzi positivi e negativi per apprendere abilità o facoltà molto diverse tra loro come il linguaggio, il senso morale, la cognizione numerica e così via (cfr. gli scritti di Skinner, padre del comportamentismo). L’esperienza che l’uomo fa del mondo sarebbe per tanto fonte di informazione sufficientemente ricca per i meccanismi di acquisizione generali per dominio.
La visione alternativa all’empirismo, il nativismo, mette in dubbio che l’informazione disponibile al bambino sia sufficientemente ricca per apprendere attraverso rinforzi positivi e negativi, semplici associazioni, o altri meccanismi dominio generali, una serie di abilità o tratti psicologici. Secondo il nativismo, vi sarebbe un’ampia costellazione di meccanismi di apprendimento di carattere specifico per dominio (Margolis & Laurence, 2013). Naturalmente, con ‘specifico per dominio’ si intende caratterizzare un meccanismo di apprendimento come un meccanismo che a sua volta non dipende da un apprendimento generale per dominio.
Ad esempio, un cucciolo di scoiattolo, per acquisire l’abilità di nascondere le noci scavando nel terreno, non ha bisogno di sfruttare l’esperienza e osservare il comportamento degli altri scoiattoli, perché è dotato di un meccanismo di apprendimento specifico per dominio che garantisce l’apprendimento di una simile capacità anche senza alcuna esposizione al contesto. Infatti, gli scoiattoli cresciuti in cattività, isolati rispetto ai conspecifici, e privati dell’esperienza del contatto con un terreno che possa essere scavato, sviluppano ugualmente la capacità di scavare e anzi la esercitano inutilmente (Eibl-Eibesfeldt, 1989).
L’esempio dello scoiattolo è estremo, e certamente non tutti i meccanismi di apprendimento specifici per dominio possono fare a meno di qualsivoglia esposizione all’ambiente. Ad esempio, secondo la teoria dello sviluppo del linguaggio offerta da Noam Chomsky, esisterebbe negli esseri umani un meccanismo di apprendimento innato e specifico per il linguaggio che nondimeno deve interagire con l’esperienza affinché il bambino inizi a parlare una lingua. Il vantaggio di avere un meccanismo di apprendimento specifico è permettere una rapida acquisizione della facoltà, poiché anche una scarsa informazione ambientale, grazie ai vincoli interpretativi imposti dai meccanismi specifici (che i meccanismi generali per dominio non saprebbero imporre con la stessa rapidità), è sufficiente a garantire la maturazione.
Recentemente, tuttavia, sono stati sviluppati dei modelli probabilistici dell’apprendimento che, pur rappresentando una versione dell’approccio empirista, si caratterizzano per una maggiore capacità di risposta alla critica della povertà dello stimolo (ovvero, la critica che chiede ragione di come i meccanismi generali per dominio possano spiegare il rapido sviluppo di molte facoltà umane in presenza di un’esposizione all’ambiente che secondo i nativisti è limitata e insufficiente – in alcuni casi parliamo di poche ore).
I modelli probabilisti cercano di spiegare un insieme sempre più vasto di capacità cognitive superiori (come, ad esempio, il linguaggio, il ragionamento causale, etc.) sfruttando i vincoli imponibili dalla matematica della statistica bayesiana all’interpretazione dell’informazione proveniente dall’ambiente. La cognizione è dunque intesa come un insieme di processi che traggono inferenze a partire dall’informazione ambientale secondo una logica normativa o una razionalità che è giustificabile dalla teoria della probabilità. In particolare, queste inferenze seguirebbero il teorema di Bayes, il quale permetterebbe di ricavare la probabilità a posteriori che una certa ipotesi H sia vera posto che un certo insieme di dati D è stato osservato. Indichiamo con p(H|D), ovvero la probabilità di H condizionato a D, la probabilità a posteriori (anche p(H|D) = [p(HՈD)/p(D)]). La formula di Bayes prevede che p(H|D) sia proporzionale al prodotto della probabilità a priori p(H), ovvero la probabilità che l’ipotesi H sia vera prima di osservare i dati, e della probabilità di osservare i dati D assumendo l’ipotesi H come vera, ovvero p(D|H).
Quello che è importante notare è soprattutto che la probabilità di prendere come vera una certa ipotesi dipende non solamente dai dati che abbiamo a disposizione, ma anche dalle assunzioni a priori che abbiamo fatto. Ecco perché il calcolo delle probabilità bayesiano, se fosse uno strumento naturalmente a disposizione del nostro cervello per interpretare la realtà, eviterebbe lunghi calcoli (formali e matematici, che verrebbero operati a livello chiaramente inconscio) e difficili interpretazioni dell’ambiente. Perché le ipotesi e assunzioni a priori, rappresentando un vincolo interpretativo per la cognizione dell’uomo, restringerebbero il campo delle possibili ipotesi da ritenere coerenti con o esplicative dell’informazione raccolta dal bambino nella sua interazione con l’ambiente circostante. Inoltre, il potere di questi modelli di apprendimento risiederebbe nel fatto che già con poche occorrenze di un certo dato, il meccanismo di calcolo probabilistico sarebbe in grado di individuare l’interpretazione o la spiegazione maggiormente probabile, pur in presenza di diverse ipotesi tutte coerenti con i dati osservati.
Facciamo un esempio per capire meglio il ragionamento. L’esempio che segue è un esempio di size principle. Innanzitutto, osservate la figura qui riportata, e meditate per un momentino sulla misticità del suo genio; il significato ne diverrà poi chiaro.
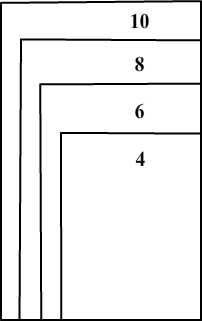
Immaginate di avere quattro dadi (non truccati), ognuno con un numero differente di facce (4, 6, 8, 10). Lanciando un dado a caso per 10 volte consecutive ottenete una serie di numeri compresa tra 2 e 4. Risulta immediatamente evidente che il dato scelto a caso tra i quattro a disposizione è improbabile che sia quello con 10 facce, poiché sarebbe veramente un caso eccezionale non aver ottenuto numeri superiori al 4. Il size principle non farebbe altro che specificare l’ampiezza della probabilità che una certa ipotesi sia vera nel modo che possiamo vedere in figura. L’ipotesi che il dato abbia quattro facce (H4) ha un’ampiezza di probabilità maggiore rispetto all’ipotesi che il dato abbia, ad esempio, sei facce (H6).
Ora immaginate un caso più simile all’esperienza che generalmente facciamo del mondo, dove raramente abbiamo la possibilità di osservare molte occorrenze di un certo fenomeno, o, in ogni caso, l’apprendimento si verifica anche in assenza di informazione ridondante. Immaginate, dunque, di osservare un solo risultato: il dato restituisce un valore inferiore o uguale a 4. Il risultato è spiegabile da tutte le ipotesi, tanto da H4 che da H10. Tuttavia, la probabilità di osservare un numero inferiore o uguale a 4 sotto H4 è 0.25, ovvero maggiore della probabilità sotto H10, che è 0.10. Se poi aggiungiamo un’altra osservazione dove nuovamente il risultato è uguale o inferiore a 4, le probabilità si elevano alla seconda, distanziandosi ulteriormente tra loro. Con tre osservazioni, le probabilità delle due ipotesi H4 e H10 si elevano alla terza (H4 = 0.0156 e H10 = 0.001), rendendo la scelta, per un cervello che disponga di meccanismi che obbediscono al calcolo della probabilità, semplice anche con poche informazioni.
Nichols e collaboratori, in un recente articolo su Mind & Language, hanno argomentato che la stessa acquisizione delle regole morali potrebbe essere guidata da meccanismi di apprendimento che sfruttano la matematica del calcolo della probabilità, così come l’abbiamo brevemente esposto (Nichols, Kumar, Lopez, Ayars, & Chan, 2016). L’obbiettivo è spiegare come il bambino riesca a generalizzare correttamente e comprendere la regola dalle diverse esperienze di punizioni, rimproveri o eventuali lodi e ricompense da parte dei genitori o della scuola.
Ad esempio, se vengo biasimato per aver danneggiato la proprietà di altri, o se mi si impone di non danneggiare la proprietà altrui (molto spesso, una specifica proprietà altrui), posso interpretare la regola in diversi modi. Posso pensare che la regola abbia lo scopo di a) vietare il danno da me causato intenzionalmente; b) vietare il danno da me causato (dunque anche quello causato accidentalmente); oppure c) vietare il danno (dunque anche quello da me non causato, come ad esempio un disastro naturale). Come fa il bambino a comprendere dall’esperienza che il divieto del genitore è mirato ad evitare il danno intenzionale, o comunque che la regola morale si impone contro il danno intenzionale?
Poiché la scopo della regola (a) è più ristretto rispetto alla scopo della regola (b) o a quello della regola (c), abbiamo la seguente situazione. Immaginando di avere a disposizione alcuni casi dove è biasimata l’azione intenzionale che porta al danno, un meccanismo di apprendimento bayesiano che rispondesse al size principle dovrebbe assegnare una maggiore probabilità all’ipotesi per cui lo scopo della regola è ristretto. In questo senso, possiamo paragonare l’ipotesi (a) a H4 (dall’esempio del lancio dei dati) e l’ipotesi (c) a H10. Già poche osservazioni basterebbero per rendere sospetta o improbabile l’ipotesi con lo scopo più generale (ovvero che la regola vieti il danno in sé), se queste osservazioni sono tutti casi di danno intenzionale. Ovviamente, chi si impegna in questa ricostruzione dell’apprendimento del giudizio morale, deve anche impegnarsi a postulare uno spazio di probabilità a priori ed un meccanismo innato che risponde alle logiche della teoria della probabilità.
Giunti a questo punto della discussione, e avendo considerato il vantaggio principale dei modelli di apprendimento probabilisti, ovvero la capacità di spiegare l’apprendimento con un meccanismo generale per dominio che funzioni anche in condizioni di scarsità di stimoli o informazioni, possiamo ora concentrarci sui punti deboli di un tale approccio. I punti critici sono principalmente due (Marcus & Davis, 2013).
La prima criticità è relativa alla selezione dei compiti sperimentali attraverso i quali si verifica l’aderenza della risposta dei soggetti alle predizioni dei modelli bayesiani. L’impressione è che, nella letteratura esistente, si siano selezionati quei compiti che permettessero di registrare delle risposte da parte dei soggetti ben prevedibili dai modelli probabilistici, e che poi si sia proceduto a generalizzare dalla capacità dei modelli di predire le risposte a certi compiti alla capacità dei modelli di predire le risposte a compiti simili ma non certamente uguali all’interno di un certo dominio psicologico. Con il risultato che, nonostante le dichiarazioni dei sostenitori dei modelli di apprendimento probabilistici, non sia affatto stabilita la potenza dei modelli rispetto a un numero sufficiente di casi per una qualsivoglia facoltà umana (ad es. l’apprendimento delle parole).
Un secondo punto critico è relativo alla scelta dei modelli. Come abbiamo visto, la capacità del modello di aderire alle risposte dei soggetti dipende dalla scelta delle ipotesi e delle probabilità a priori, e tuttavia queste vengono scelte a posteriori, con il risultato che il ragionamento delle persone poi viene spesso ritenuto razionale (secondo le norme del calcolo della probabilità) proprio perché si sono scelte ipotesi a priori che potessero fare al caso. Questo non sarà sempre il caso, ma c’è il rischio che spesso lo sia.
Ovviamente l’argomento qui è complesso, e non pretendiamo di liquidare in poche righe la pratica di selezione delle probabilità a priori. Ma ecco un esempio. In uno studio, ai partecipanti è stato chiesto di immaginare che un certo film avesse guadagnato sino ad un certo momento una certa somma di denaro al botteghino (1/6/10/40/100 milioni di dollari), e di predire il guadagno totale del film (Griffiths & Tenenbaum, 2006). Dopodiché, l’aderenza del modello probabilistico ai dati raccolti è stata vincolata all’assunzione che i guadagni di un film sono uniformemente distribuiti nel tempo. Sicché, la razionalità delle previsioni dei soggetti stabilita dall’aderenza del modello alle risposte dei soggetti è vincolata rispetto alla verità dell’affermazione che i film guadagnano seguendo un incremento lineare. Tuttavia, per molti film quest’affermazione è falsa. Infatti, i film guadagnano una buona percentuale del ricavo totale nei primi tempi dopo l’uscita nei cinema.
In conclusione, l’idea che l’apprendimento possa essere spiegato da meccanismi generali per dominio che obbediscono ad una razionalità di tipo probabilistico è certamente stimolante, ma forse oggi ancora debole, se considerata alla luce delle problematiche che abbiamo considerato. Una mole di evidenza empirica (che, per motivi di spazio, non ci è qui possibile passare in rassegna), invece, ci convince della plausibilità di postulare dei modelli di apprendimento specifici per dominio nella spiegazione dello sviluppo di una numerosa serie di tratti e capacità psicologiche. Il giudizio morale è probabilmente da annoverare nell’insieme di queste capacità il cui sviluppo è meglio spiegabile da una visione nativista dell’apprendimento delle facoltà mentali.
Bibliografia minima:
-Eibl-Eibesfeldt, I. (1989). Human ethology. New York: Aldine de Gruyter.
-Griffiths, T., & Tenenbaum, J. (2006). Optimal predictions in everyday cognition. Psychological Science, 17, 767-773.
-Marcus, G., & Davis, E. (2013). How robust are probabilistic models of higher-level cognition? Psychological Science, 24, 2351-2360.
-Margolis, E., & Laurence, S. (2013). In defence of nativism. Philosophical Studies, 165, 693-718.
-Nichols, S., Kumar, S., Lopez, T., Ayars, A., & Chan, H. (2016). Rational learners and moral rules. Mind & Language, 31, 530-554.
_______________________________________________________
Francesco Margoni


Be First to Comment